本文是mybatis框架一个初步的入门总结,最全的最好的资料应该参考这个
本文在Eclipse下搭建一个小程序可以测试mybatis对mysql数据库进行增删改查这几个基本功能。
1.首先建立数据库,我建立的数据库叫test,编码是UTF-8,里面有两张表,它们是这样的:
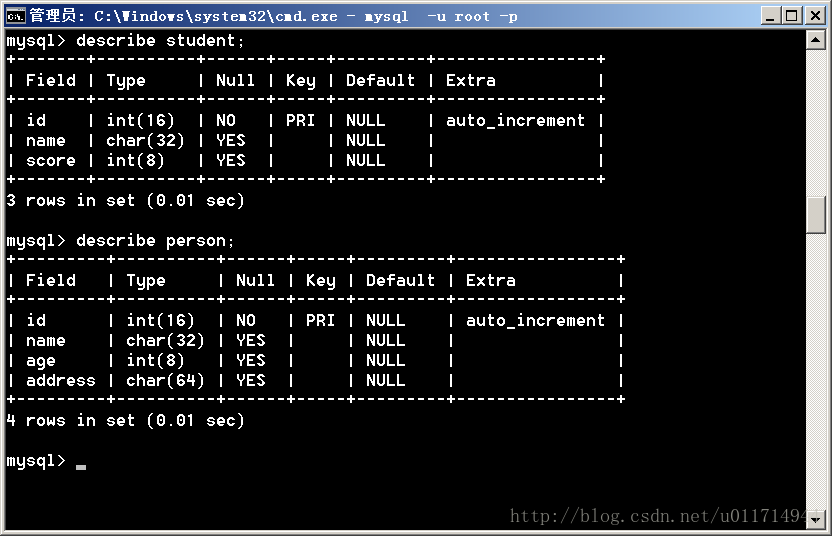
两张表的数据我填的是这样的,当然可以随便填,不过最好在person中有1个以上name相同的,后面会用到:
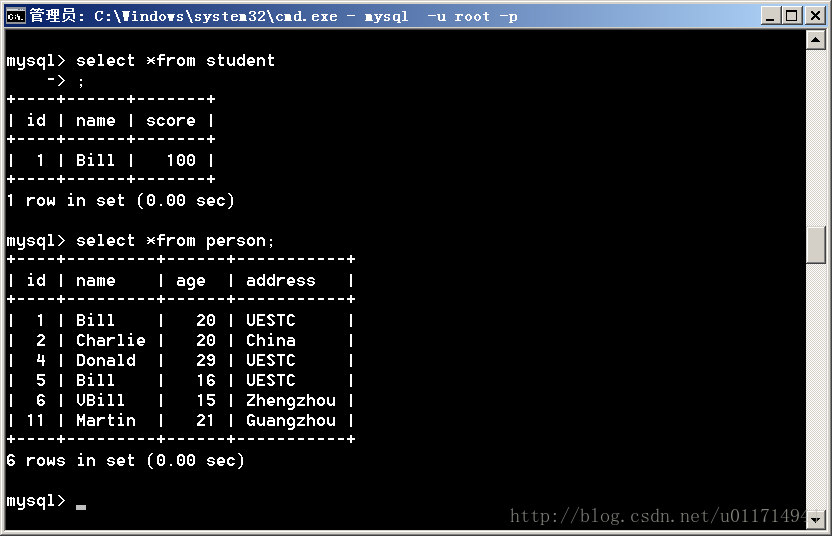
2.在ECLIPISE下建立DYNAMIC WEB PROJECT,别忘了在BUILD PATH下加入mybatis和mysql的jar包。这个工程的布局是这样的:
文件和类的用途后面解释
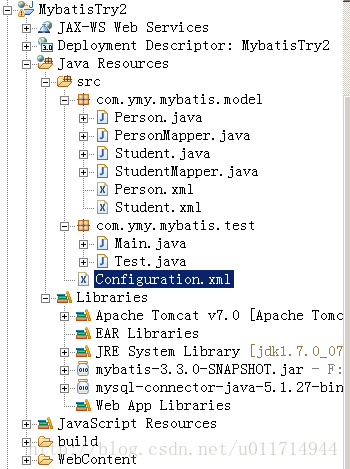
Main里面有程序的static void main函数。Test类封装了测试mybatis框架功能的函数。xml都是框架的配置文件。Person与Student是DTO数据传输对象。两个Mapper类都是接口类,用途后面讲。
3.配置Configuration.xml。在src文件夹下先建立这个文件。
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE configuration PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
<typeAliases>
<typeAlias alias="Person" type="com.ymy.mybatis.model.Person"/>
<typeAlias alias="Student" type="com.ymy.mybatis.model.Student"/>
<!-- short name of java classes -->
</typeAliases>
<environments default="development">
<environment id="development">
<!--
choose any name for default and id
-->
<transactionManager type="JDBC"/>
<dataSource type="POOLED">
<property name="driver" value="com.mysql.jdbc.Driver"/>
<property name="url" value="jdbc:mysql://127.0.0.1:3306/test"/>
<property name="username" value="root"/>
<property name="password" value="31415926"/>
<property name="driver.encoding" value="UTF8"/>
<!--property name="PROPERTY NAME" value="${var name}"/-->
</dataSource>
</environment>
</environments>
<mappers>
<mapper resource="com/ymy/mybatis/model/Person.xml"/>
<mapper resource="com/ymy/mybatis/model/Student.xml"/>
<!-- xml of mapper class -->
</mappers>
</configuration>标签解释:
<typeAliases> 定义的是别名,全名是type里的一大串,起个别名减少了后面的书写量。
<environments>和<environment>配置了数据库的信息,一个environments下可以配多个environment来访问多个数据库,这超出了本文讨论范围。这个文章:http://zhangbo-peipei-163-com.iteye.com/blog/2052924讲了多数据源配置。
<property name>和value改成自己的数据库的就行了
<mappers>下定义多个<mapper>每个mapper对应一个DTO类型,以及它们对应的数据库操作。mapper resource后面是对应DTO的xml文件的实际位置。3.建立DTO类Student和Person。
Student类:
package com.ymy.mybatis.model;
public class Student {
private int id;
private String name;
private int score;
public Student() {
}
public int getID() {
return id;
}
public void setID(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getScore() {
return score;
}
public void setScore(int score) {
this.score = score;
}
}Person类:
package com.ymy.mybatis.model;
public class Person {
private int id;
private String name;
private int age;
private String address;
public Person(String name, int age, String address) {
this.name = name;
this.age = age;
this.address = address;
}
public Person(int id, String name, int age, String address) {
this.id = id;
this.name = name;
this.age = age;
this.address = address;
}
public Person() {
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public String getAddress() {
return address;
}
public void setUserAddress(String userAddress) {
this.address = userAddress;
}
}4.配置Student.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.ymy.mybatis.model.StudentMapper">
<select id="selectStudentByID" parameterType="int" resultType="Student">
select * from student where id = #{id}
</select>
</mapper>解释:< mapper namespace >那句,相当于在命名空间com.ymy.mybatis.model.StudentMapper下定义了一个叫selectStudentByID的语句,它接收的参数类型(parameterType)为int,返回类型为Student。到后面我们定义了接口类StudentMapper,mybatis就会把接口中的函数和xml中的定义绑定。< select >标签说明这是查询类型的操作。
接口类StudentMapper:
package com.ymy.mybatis.model;
public interface StudentMapper {
public Student selectStudentByID(int id);
}配置Person.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.ymy.mybatis.model.PersonMapper">
<resultMap id="personResultMap" type="Person">
<id property="id" column="id" />
<result property="name" column="name"/>
<result property="age" column="age"/>
<result property="address" column="address"/>
</resultMap>
<select id="selectPersonByID" parameterType="int" resultType="Person">
select * from person where id = #{id}
</select>
<select id="selectPersonByName" parameterType="String" resultMap="personResultMap">
select * from person where name = #{name}
</select>
<select id="lastInsertId" resultType="int">
select last_insert_id()
</select>
<insert id="addPerson" parameterType="Person">
insert into person (id,name,age,address)
values (NULL,#{name},#{age},#{address})
</insert>
<update id="updatePerson" parameterType="Person">
update person set
name = #{name},
age = #{age},
address= #{address}
where id = #{id}
</update>
<delete id="deletePerson" parameterType="int">
delete from person where id = #{id}
</delete>
</mapper>看sql语句就知道都是干啥的了,增删改查已经全了。重点是selectPersonByName。数据库里有重名的人,所以会查询到多个人。这时返回类型标签成了resultMap。值为personResultMap。文件最前面定义了personResultMap。result里面property是DTO里变量的名称。column和数据库里的名称对应。
接口类PersonMapper:
package com.ymy.mybatis.model;
import java.util.List;
public interface PersonMapper {
public Person selectPersonByID(int id);
public List<Person> selectPersonByName(String name);
public void addPerson(Person person);
public void deletePerson(int id);
public void updatePerson(Person person);
public int lastInsertId();
}5.写测试代码:
Test类:
package com.ymy.mybatis.test;
import java.io.*;
import java.util.*;
import org.apache.ibatis.io.Resources;
import org.apache.ibatis.session.SqlSession;
import org.apache.ibatis.session.SqlSessionFactory;
import org.apache.ibatis.session.SqlSessionFactoryBuilder;
import com.ymy.mybatis.model.*;
public class Test {
private static SqlSessionFactory sqlSessionFactory;
// it should be static
// every thread should have its own SqlSession instance
private static Reader reader;
static {
try {
reader = Resources.getResourceAsReader("Configuration.xml");
sqlSessionFactory = new SqlSessionFactoryBuilder().build(reader);
// every database should have its own SqlSessionFactory
} catch (Exception e) {
e.printStackTrace();
}
}
public void getPersonList(String userName) {
SqlSession session = sqlSessionFactory.openSession();
try {
PersonMapper mapper = session.getMapper(PersonMapper.class);
List<Person> people = mapper.selectPersonByName(userName);
for (Person person : people) {
System.out.print("Name: " + person.getName() + "\t");
System.out.print("Age: " + person.getAge() + "\t");
System.out.println("Addr: " + person.getAddress());
}
} finally {
session.close();
}
}
public void addPerson() {
@SuppressWarnings("resource")
Scanner inputer = new Scanner(System.in);
System.out.println("Input a person's name age and address");
String name = inputer.next();
int age = inputer.nextInt();
String address = inputer.next();
Person newPerson = new Person(name, age, address);
SqlSession session = sqlSessionFactory.openSession();
try {
PersonMapper mapper = session.getMapper(PersonMapper.class);
mapper.addPerson(newPerson);
int last_id = mapper.lastInsertId();
System.out.println("Insert id = " + last_id);
session.commit();
} finally {
session.close();
}
}
public void updatePerson() {
@SuppressWarnings("resource")
Scanner inputer = new Scanner(System.in);
System.out.println("Input a person's id, name, age and address");
int id = inputer.nextInt();
String name = inputer.next();
int age = inputer.nextInt();
String address = inputer.next();
Person person = new Person(id, name, age, address);
SqlSession session = sqlSessionFactory.openSession();
try {
PersonMapper mapper = session.getMapper(PersonMapper.class);
mapper.updatePerson(person);
session.commit();
System.out.println("OK!");
} finally {
session.close();
}
}
public void deletePerson() {
@SuppressWarnings("resource")
Scanner inputer = new Scanner(System.in);
System.out.println("Input an id to delete:");
int id = inputer.nextInt();
SqlSession session = sqlSessionFactory.openSession();
try {
PersonMapper mapper = session.getMapper(PersonMapper.class);
mapper.deletePerson(id);
session.commit();
} finally {
session.close();
}
}
public void selectPersonById(){
@SuppressWarnings("resource")
Scanner inputer = new Scanner(System.in);
System.out.println("Input an id to select:");
int id = inputer.nextInt();
SqlSession session = sqlSessionFactory.openSession();
try {
PersonMapper mapper = session.getMapper(PersonMapper.class);
Person person = mapper.selectPersonByID(id);
System.out.print("Name: " + person.getName() + "\t");
System.out.print("Age: " + person.getAge() + "\t");
System.out.println("Addr: " + person.getAddress());
} finally {
session.close();
}
}
public void selectStudentById(){
@SuppressWarnings("resource")
Scanner inputer = new Scanner(System.in);
System.out.println("Input an student id to select:");
int id = inputer.nextInt();
SqlSession session = sqlSessionFactory.openSession();
try {
StudentMapper mapper = session.getMapper(StudentMapper.class);
Student student = mapper.selectStudentByID(id);
System.out.print("Name: " + student.getName() + "\t");
System.out.print("ID: " + student.getID() + "\t");
System.out.println("Score: " + student.getScore());
} finally {
session.close();
}
}
}解释:我们通过SqlSession类的对象获取映射(使用getMapper方法),通过映射调用Student和Person接口类里的函数。SqlSession参与数据库的管理事务。当执行了修改数据库内容的语句后调用commit()方法讲更改的内容写入数据库。完成后及时关闭SqlSession对象,调用close()方法。
最后写Main类,然后运行程序:
package com.ymy.mybatis.test;
public class Main {
public static void main(String[] args) {
Test t1 = new Test();
t1.selectPersonById();
t1.getPersonList("Bill");// find Bill
t1.addPerson();
t1.deletePerson();
t1.updatePerson();
t1.selectStudentById();
}
}